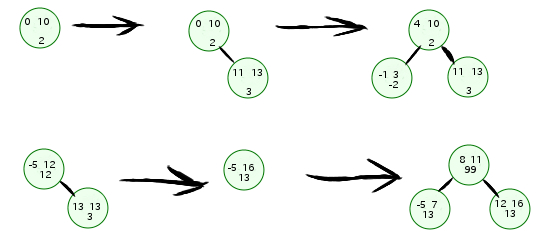
/**
* Created by green on 28.11.15.
*/
import jdk.internal.org.objectweb.asm.tree.analysis.Value;
import java.security.Key;
/**
* Created by green on 26.11.15.
*/
interface SegmentedArray<T> {
/**
* <p>Get value by element index</p>
* @param index index of element.
* @return Value of element with specified index.
*/
T get(int index);
/**
* <p>Set the same value for all elements in the specified index range</p>
* @param start the beginning index, inclusive.
* @param end the ending index, exclusive.
* @param value value for.
*/
void set(int start, int end, T value);
/**
* <p>Returns the index within this array of the first occurrence of the specified value,
* starting at the specified index. If no such value of k exists, then -1 is returned.</p>
* @param value the T-based value for which to search.
* @param fromIndex the index from which to start the search.
* @return the index within this array of the first occurrence of the element with specified value,
* starting at the specified index.
*/
int indexOf(T value, int fromIndex);
/**
* <p>Find minimum value in the specified indexes range</p>
* @param start the beginning index, inclusive.
* @param end the ending index, exclusive.
* @return Minimum value.
*/
T minValue(int start, int end);
}
class CT <Value extends Comparable<Value>> implements SegmentedArray<Value>{
private class Node {
Value value;
int l, r;
Node left, right, father;
public Node (Value value, Node father, int l, int r) {
this.value = value;
this.left = this.right = null;
this.father = father;
this.l = l; this.r = r;
}
}
private Node root;
private Node add (Node node,Value value, Node father, int l, int r){
if (node == null){
Node newnode = new Node(value,father, l , r);
return newnode;
}
//int compareResultl = l.compareTo(node.l);
//int compareResultr = r.compareTo(node.r);
if(l > node.r){
node.right = add(node.right, value, node, l, r);
}else if(r < node.l){
node.left = add(node.left, value, node, l, r);
}else if(l >= node.l && r <= node.r){
if(l == node.l && r == node.r){
node.value = value;
return node;
}else if(l == node.l){
node.right = add(node.right, node.value, node, r+1, node.r);
node.value = value;
node.r = r;
}else if(r == node.r){
node.left = add(node.left, node.value, node, node.l, l-1);
node.value = value;
node.l = l;
}else{
Node newnode = new Node(value,father, l , r);
newnode.left = node.left;
newnode.right = node.right;
newnode.left = add(newnode.left, node.value, newnode, node.l, l-1);
newnode.right = add(newnode.right, node.value, newnode, r+1, node.r);
node = newnode;
}
}else if(l < node.l && r > node.r){
node.value = value;
node.l = l;
node.r = r;
node.left = delete(node.left, l, false);
node.right = delete(node.right, r, true);
}else if(l < node.l){
if(r == node.r){
node.value = value;
node.l = l;
node.left = delete(node.left, l, false);
}else{
node = add(node, node.value, father, r+1, node.r);
node = add(node, value, father, l, r);
}
}else if (r > node.r) {
if (l == node.l) {
node.value = value;
node.r = r;
node.right = delete(node.right, r, true);
} else {
node = add(node, node.value, father, node.l, l - 1);
node = add(node, value, father, l, r);
}
}
return node;
}
public void set(int l, int r, Value value) {
root = add(root, value, null, l, r);
}
private Node delete(Node node, int d, Boolean side){
if(node == null) return null;
if(d < node.r && d > node.l){
node = add(node, node.value, node.father, node.l, d - 1);
node = delete(node, d, side);
}else if(d < node.l){
if(side)
node.left = delete(node.left, d, side);
else {
node = node.left;
node = delete(node, d, side);
}
}else if(d > node.r){
if(side) {
node = node.right;
node = delete(node, d, side);
}else
node.right = delete(node.right, d, side);
}else if(d == node.r){
if(side) {node = node.right;} else {node.right = null;node.r = d - 1;}
}else if(d == node.l){
if(side) {node.left = null;node.l = d + 1;} else {node = node.left;}
}
return node;
}
private Value get(Node node, int index){
if(node == null) return null;
if(index > node.r)
return get(node.right, index);
else if (index < node.l)
return get(node.left, index);
else
return node.value;
}
public Value get(int index) {
return get(root, index);
}
private Value minimum(Value x, Value y){
if(x == null && y == null) return null;
else if(x == null) return y;
else if(y == null) return x;
else {
if (x.compareTo(y) == 1) return y;
else return x;
}
}
private Value min(Node node, int start, int end){
if(node == null) return null;
if(end < node.l){
return min(node.left, start, end);
}else if (start > node.r){
return min(node.right, start, end);
}else{
Value v1 = null, v2 = null;
if(start < node.l) v1 = min(node.left, start, end);
if(end > node.r) v2 = min(node.right, start, end);
return minimum(v2, minimum(node.value, v1));
}
}
public Value minValue(int start, int end){
return min(root, start, end);
}
private Integer indexOf(Node node, Value value, int index){
if(node == null) return null;
if(index <= node.r) {
Integer v = null;
if(index < node.l){
v = indexOf(node.left, value, index);
if (v != null) return v;
}
if (value == node.value) return Math.max(node.l, index);
v = indexOf(node.right, value, index);
if (v != null) return v;
}
return indexOf(node.right, value, index);
}
public int indexOf(Value value, int index){
return indexOf(root, value, index);
}
private void print(Node node, int level) {
if (node != null) {
print(node.right,level+1);
for (int i=0;i<level;i++) {
System.out.print("\t");
}
System.out.println(node.l + "-" + node.r + "->" + node.value);
print(node.left,level+1);
}
}
public void print() {
print(root,0);
}
}
public class Tree_cut {
public static void main(String[] args) {
CT<Integer> tree = new CT<>();
long start, end;
start = System.nanoTime();
tree.set(50, 4566, 14);
//tree.set(130, 740, 29012);
//tree.set(1000, 1084, -2);
//tree.set(3006, 3070, 51);
end = System.nanoTime();//tree.set(50, 4566, 14);
System.out.println("Первый Set в BigSegmentedArray отрабатывает за " + (end - start) + " нс.");
start = System.nanoTime();
Integer get = tree.get(111);
end = System.nanoTime();
System.out.println("Get в BigSegmentedArray отрабатывает за " + (end - start) + " нс.");
System.out.println(get);
start = System.nanoTime();
tree.set(76, 830, 1);
end = System.nanoTime();
System.out.println("Второй Set в BigSegmentedArray отрабатывает за " + (end - start) + " нс.");
tree.set(60, 92, 0);
start = System.nanoTime();
int minimum = tree.minValue(130, 1400);
end = System.nanoTime();
System.out.println("Min в BigSegmentedArray отрабатывает за " + (end - start) + " нс.");
System.out.println(minimum);
tree.print();
}
}